서론
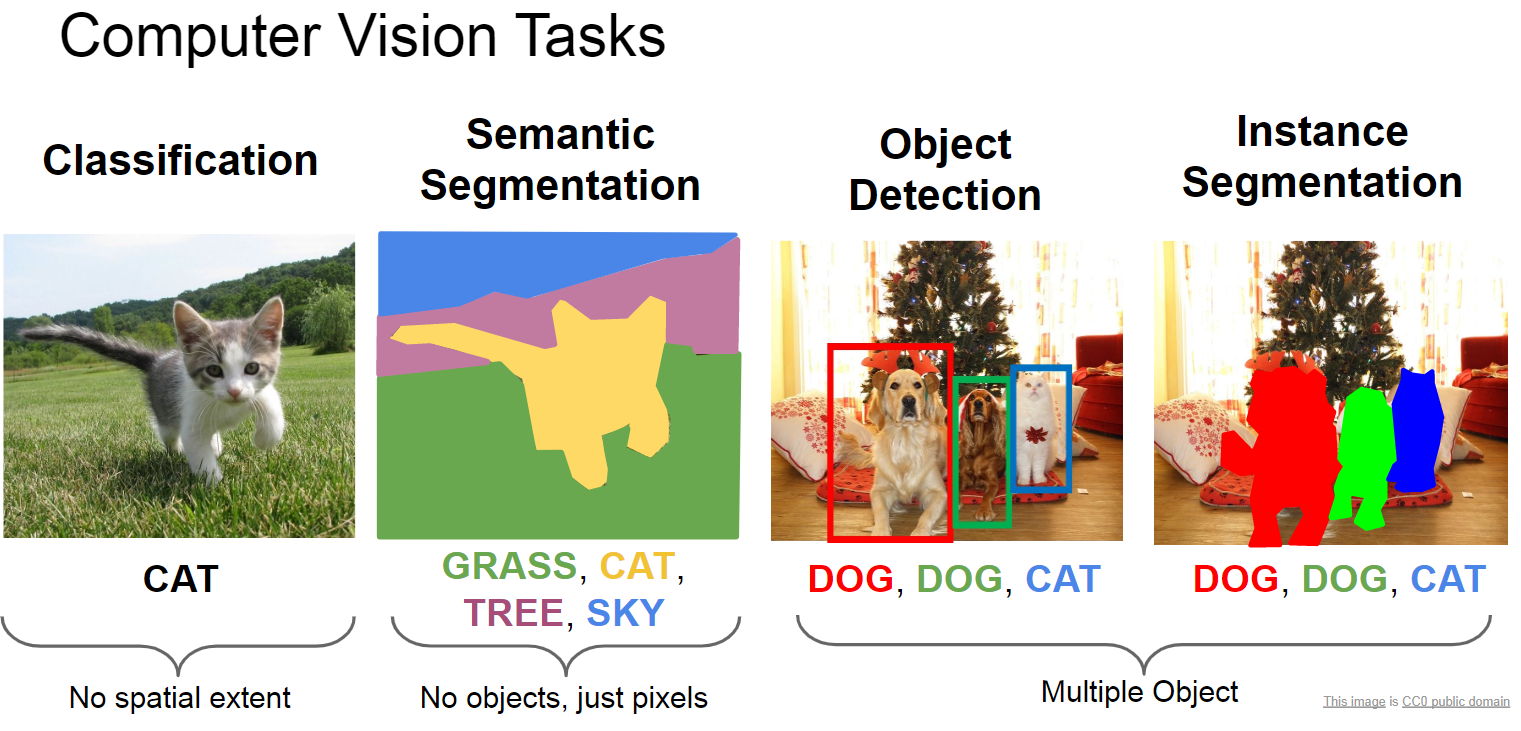
객체 탐지는 컴퓨터 비전 분야에서 가장 활발히 연구되고 있는 주제 중 하나입니다. 실시간 비디오 분석부터 자율 주행 차량, 보안 감시 시스템에 이르기까지 객체 탐지 기술은 다양한 분야에서 필수적인 역할을 하고 있습니다. 최근 딥러닝의 발전으로 객체 탐지 기술은 눈부신 성장을 이루었습니다. 본 글에서는 딥러닝 기반의 객체 탐지 방법론에 대해 소개하고, 그 발전 과정과 현재의 최신 동향에 대해 탐구해보겠습니다.
객체 탐지란?
객체 탐지는 이미지나 비디오 내에서 다양한 객체를 식별하고 분류하는 기술입니다. 이는 단순히 객체가 존재하는지 여부를 판단하는 것을 넘어, 그 위치를 정확히 파악하고, 주변 객체와의 관계를 이해하는 것까지 포함됩니다.
딥러닝의 등장
딥러닝 기술이 객체 탐지 분야에 도입되기 전까지, 객체 탐지는 주로 수동으로 설계된 특징(feature)에 기반하여 수행되었습니다. 하지만 이러한 방법은 복잡하고 다양한 시나리오에 적용하기 어려웠습니다. 딥러닝, 특히 합성곱 신경망(Convolutional Neural Networks, CNN)의 등장은 이러한 한계를 극복하고, 객체 탐지의 정확도와 효율성을 대폭 향상시켰습니다.
주요 딥러닝 기반 객체 탐지 모델
1. R-CNN과 그 변형들
R-CNN(Regions with CNN features)은 객체 후보 영역을 추출한 후, 각 영역에 대해 CNN을 적용하여 객체를 분류하는 방식을 사용합니다. 이후 Fast R-CNN, Faster R-CNN 등의 개선 모델이 등장하여 처리 속도와 정확도를 더욱 향상시켰습니다.
2. YOLO(You Only Look Once)
YOLO는 이미지를 한 번만 보고도 객체의 종류와 위치를 실시간으로 탐지할 수 있는 모델입니다. 이미지 전체를 그리드로 나누고, 각 그리드 셀별로 객체의 존재 확률과 바운딩 박스를 예측합니다. 빠른 속도와 높은 정확도로 많은 인기를 얻었습니다.
3. SSD(Single Shot MultiBox Detector)
SSD는 다양한 크기의 특징 맵에서 객체를 탐지하여, 다양한 크기의 객체를 효과적으로 탐지할 수 있습니다. YOLO와 유사하게 단일 네트워크를 사용하여 빠르게 객체를 탐지할 수 있는 장점이 있습니다.
최신 동향
객체 탐지 기술은 계속해서 발전하고 있으며, Transformer 기반의 모델들이 새로운 패러다임으로 떠오르고 있습니다. 예를 들어, ViT(Visual Transformer)와 같은 모델들은 이미지 내의 시각적 요소들 사이의 관계를 더 깊이 이해하려는 시도를 하고 있습니다. 이러한 모델들은 객체 탐지뿐만 아니라 이미지 내 객체 간의 복잡한 관계와 상황을 이해하는 데에도 큰 잠재력을 보여주고 있습니다.
결론
딥러닝 기반 객체 탐지 기술의 발전은 계속해서 컴퓨터 비전 분야에 혁신을 가져오고 있습니다. 이러한 기술의 발전은 단지 기술적인 발전에만 그치지 않고, 의료, 보안, 교통 등 인류의 삶의 질을 향상시키는 다양한 응용 분야에 긍정적인 영향을 미치고 있습니다. 앞으로도 딥러닝 기반 객체 탐지 기술의 발전과 그 응용 분야의 확장에 주목해보는 것은 매우 흥미로운 연구 주제가 될 것입니다.
'딥러닝 tutorial' 카테고리의 다른 글
| Faster R-CNN과 PyTorch로 시작하는 객체 탐지 (0) | 2024.02.23 |
|---|---|
| 딥러닝 기반 객체 탐지의 새 지평: RCNN, YOLO, SSD를 넘어서 (0) | 2024.02.23 |
| SSD와 PyTorch로 시작하는 객체 탐지 (1) | 2024.02.23 |
| 딥러닝 기반 객체 탐지: R-CNN과 PyTorch를 활용한 실전 예제 (0) | 2024.02.23 |
| YOLO를 활용한 PyTorch 객체 탐지 튜토리얼 (0) | 2024.02.23 |



